S3+Apache Zeppelinでお手軽データ分析②

コラビットの川原です。
前回はApache Zeppelinを使ってS3からデータを取り込み分析するにあたっての準備を行いました。
今回は、早速分析を行ってみようと思います。
kaggleに面白いデータがあったので、今回使ってみます。(TVゲームの売り上げデータです。仕様についてはkaggleを直接ご覧ください)
https://www.kaggle.com/kendallgillies/video-game-sales-and-ratings
データセットをダウンロードして適当なS3のバケットに放り込みます。
データを読み込む
まず、データを読み込み、SQL temporary viewとして登録します。
SQL temporary viewとして登録することにより、SQLを使ってデータの取り出しができるようになるので便利です。
コード内では高速化のためcacheを使うようにもしてあります
前回のパラグラフ(awsAccessKeyIdの設定)に続けて、新しいパラグラフを追加し、下記のコードを記述してください。
[scala]
%spark
val endPoint = "s3n://batch.how-ma.com/zeppelin/for_blog/Video_Game_Sales_as_of_Jan_2017.csv"
val df = spark
.read
.option("header", true)
.option("inferSchema", true)
.option("nullValue", "NULL")
.csv(endPoint)
df.cache
df.createOrReplaceTempView("game_sales")
[/scala]
実行ボタンを押すとパラグラフの下部のoutput部分に実行結果が対話的に出力されます。
SQLでデータを取得する
みなさまご存知SQLでデータの中身をみていきたいと思います。
まずは、ファミコンソフトの日本での売り上げランキング(30位まで)をみてみたいと思います。
[sql]
%sql
select * from game_sales
where Platform = ‘NES’ — NESはファミコンのことです。
order by JP_Sales desc
limit 30
[/sql]
%sqlの部分はこれがspark-sqlの実行であることを示しています。Output exceedsの警告が表示されますが、実行結果がテーブル表示されるはずです。
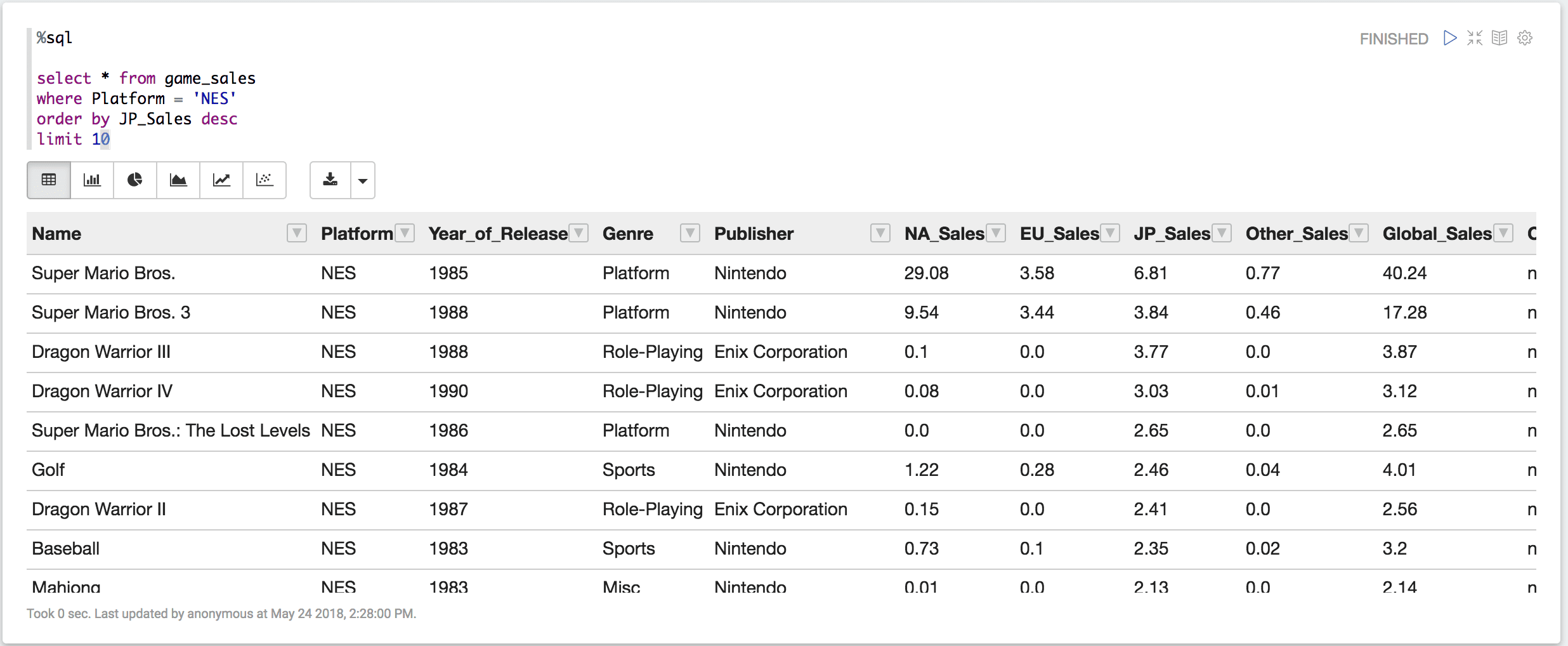
どうやら、Super Mario Brosが一位で、続いて、Super Mario Bros. 3、Dragon Warrior III、…と続いているようです。(Dragon Warriorはドラクエのことですね)
どのゲームも有名なゲームです。
次に、年次のスーファミの売り上げについてみていきたいと思います。次のコードを新しいパラグラフで実行してみてください。
[sql]
%sql
select Year_of_Release, Genre, SUM(JP_Sales) as sales from game_sales
where Platform = ‘SNES’
group by Year_of_Release, Genre
[/sql]
実行後、コードとテーブルの間にあるボタンの中からArea Chartのボタンを選択してください。
そしてsettingsでは、keysをYear_of_Releaseに、groupsをGenreに、valuesをsalesに指定してください。
そうすると、実行結果がグラフで表示されます。
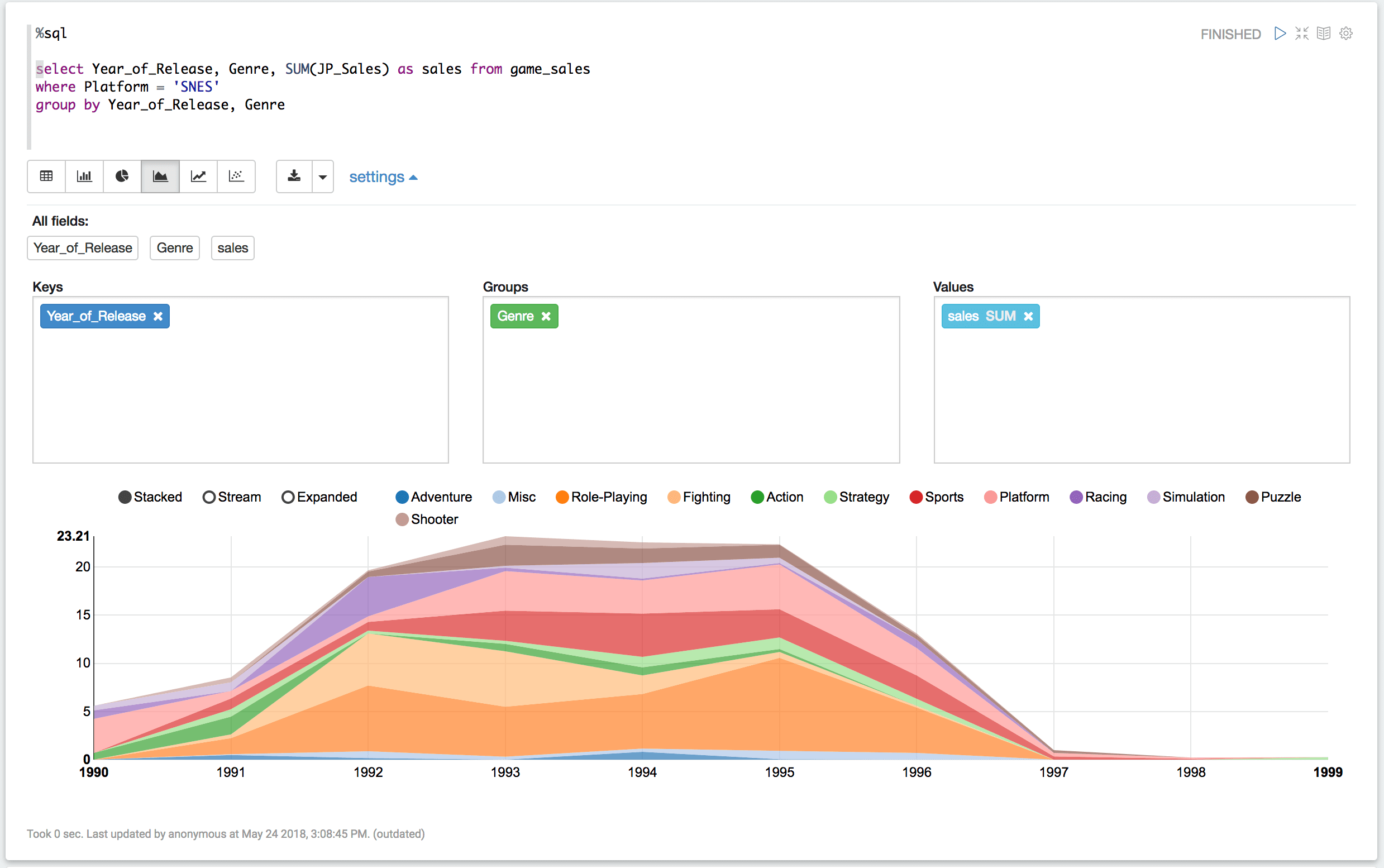
縦軸の単位は百万米ドルです。横軸が時系列(年)です。
一番高い1993年の売り上げは1967万ドルだったようです。1993年12月時点で1ドル110円くらいだったようなので、計算すると25億5310万円ですね。他のハードが発売されてソフトが少なくなったのか、1997年以降の売り上げは寂しいものとなっています。
また、売り上げの割合とてはRPG、Fighting、Sports,Platform系のゲームが多いようです。(Platformはおそらく任天堂がだしているゲームをさすようです。Donkey Kong CountryやSuper Mario Worldが該当ソフトでした)
このようにSQLを入力してからすぐにグラフ描写で視覚的にデータの特徴を確認できて、大変便利です。
他にも色々できます。
JDBC Interpreterを設定することでMySQLなどのDBに直接SQLを実行してデータを持ってきたり、Pythonでも実行できたり、数式も出力できたり、色々できることがあります。
Jyupter notebookのようにSQLに変数を記述して、処理を動的に実行できる、form Templatesの仕組みなども便利です。
今回は、紹介しませんでしたが、機械学習のアルゴリズムの実行もspark MLlibを使うことでもちろん可能です。
便利なツールなのでもっと普及することを願っています。